SEO & CRM Director at Cadastra. Atua no mercado digital desde 2001 em projetos de diversos segmentos. Na Cadastra, é responsável pelo Experience Hub que é composto pelas áreas de SEO e User-Centered Design. Já atuou em projetos para Vivo, Lojas Renner, Insper, Abril, Petrobras, entre outros.
As ferramentas de busca existem desde o início da internet. E, desde o seu início, também existem profissionais estudando essas ferramentas e quais as melhores práticas para gerar resultados através deste canal. O objetivo deste artigo é mostrar como funciona o tempo de vida de uma palavra-chave. Ou seja, desde o momento onde o Google “conhece” o termo, até o retorno na busca — sob o olhar dos olhos de um engenheiro de rankings.
O conteúdo é totalmente baseado na palestra do Googler Paul Haahr, no SMX West, cuja a apresentação pode ser conferida na palestra abaixo:
O tempo de vida de uma palavra-chave é dividido em duas partes: pré-busca, que é a parte mais fácil; e o processamento de uma palavra-chave, que já é mais complicado.
Pré-busca
A etapa pré-busca consiste no rastreamento (crawling) da internet pelo Googlebot e suas variações (mobile, news, image e etc). Após essa etapa, as páginas são analisadas passando por um processo de extração dos links, renderização do conteúdo e interpretação sobre as notações semânticas (conexões do conteúdo com entidades e outros elementos do Knowledge Graph).
Com essas informações, o índice de busca é gerado e este funciona como um índice de um livro, sendo que para cada palavra, uma lista de páginas aparece/conecta com ela. O índice é distribuído entre grupos de milhares de páginas. Estes grupos são chamados "Shards*" e existem mais de 1.000 "Shards" para o "web index". Além dessas informações, também temos os meta-dados* dos documentos.
Processamento da palavra-chave
O processamento e entendimento da palavra-chave começa com uma análise para saber se ela possui alguma entidade vinculada e/ou um sinônimo. Neste momento o contexto é muito importante, pois ele irá segmentar e entender a necessidade do usuário.
Exemplo:
Entendimento da Keyword
Existem entidades ligadas à esta palavra-chave?
Ex: [Estádio do Corinthians], [Zacarias]
Existem sinônimos nesta palavra-chave?
Ex: [XP] -> [XP Investimentos], [XP php] - > [Instalar php no windows xp]
Contexto importa e importa muito nesta etapa:
Ex: [Manga] -> Fruta, Mangá, Manga de Roupa
Ex: [Cabo] -> Cabo de Cobre, Cabo (Lugar), Cabo Frio (Cidade), Cabo Exército
Após essa primeira etapa, entramos na fase de recuperação e score, passando primeiramente pelo envio da palavra-chave para todas as "shards".
Cada uma das "shards" retorna:
Páginas que combinam com a palavra-chave
Calcula o score para a palavra-chave + página
Retorna as top pages por score
As top pages são combinadas em uma listagem, ordenadas por score e, em seguida, passam por um ajuste fino, verificando:
Ajustes no título e meta descrição quando necessário
Inclui sitelinks + rich snippets
Verifica se existem muitos resultados similares
Desqualifica páginas spam ou com ações manuais
No final dessa fase, temos o resultado de busca em apenas ⅛ de segundo.
Certo, mas afinal, qual a função do "engenheiro de rankings"? As principais são:
Escrever os códigos para os servidores (shards*);
Procurar por novos sinais e os combiná-los com os sinais mais antigos;
Otimizar os resultados através da análise sobre as métricas;
Entender os sinais e alterar o peso deles ao longo do tempo.
Score
O score é uma nota para combinar a palavra-chave com a página do site. Os sinais são um pedaço da informação utilizada no score. Neste caso, são separados em dois grupos distintos: um independente da palavra-chave, e o outro dependente dela. Alguns exemplos de sinais independentes: PageRank, linguagem e mobile friendly. Exemplos de sinais dependentes: hits, sinônimos e proximidade (local).
Métricas
As métricas são utilizadas como guia para que a otimização dos resultados de busca aconteça. Entre ela, as principais são:
Relevância: a página responde à busca do usuário e métricas de qualidade da página (essa é a mais importante de todas);
Qualidade da página: quão bom são os resultados para esta busca;
Tempo de carregamento: quanto mais rápido, melhor.
Ainda dentro das métricas, também são utilizados pesos para os rankings. Neste peso ainda existe uma escala, chamada "Reciprocidade de Rankings":
Primeiro lugar, vale 1;
Segundo lugar, vale ½;
terceiro lugar, vale ⅓;
quarto lugar, vale ¼;
quinto lugar, vale ⅕ e assim por diante.
Todos os indicadores passam por um processo de validação, seja ele através dos "Live Experiments" ou dos "Human Raters". Os exemplos de Live Experiments são: teste A/B nos usuários ativos (o famoso sandbox), entendimento sobre a mudança no padrão de cliques e análise dos resultados. Um teste bastante conhecido foi a análise entre 42 variações da cor azul dos links nos resultados de busca para entender qual delas performa melhor. Conseguem imaginar o desafio que é interpretar estes dados?
Os Human Raters são pessoas que executam uma série de testes e análises nos resultados de busca. Durante o processo de teste, eles passam por um questionamento sobre quais são os melhores resultados para uma busca e o motivo para isso, se estes estão de acordo com os guidelines definidos pelo Google. O processo de coleta dessas informações é bastante automatizado e os engenheiros gostam de contar com a análise dos Raters para qualificar os resultados — a intuição ainda é um ponto bastante utilizado aqui.
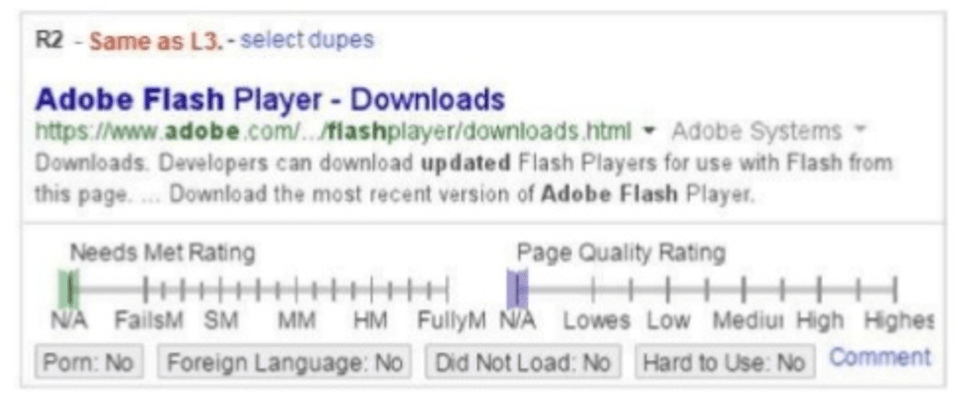
Exemplo de como a ferramenta de coleta (Radar Tools) funciona:
Rating do resultado de busca
Existem duas escalas que podem ser vistas na imagem acima. A primeira indica se o item atende às necessidades dos usuários. Já a segunda é sobre o rating da qualidade deste item.
Uma variável bastante importante sobre a necessidade do usuário é o Mobile First. Ou seja, se a página atende à necessidade e ao modelo de interação para usuários que navegam através de dispositivos móveis. Também são analisadas o dobro de palavras-chave em mobile. Além disso, também existe a preocupação com a localização.
A necessidade encontra o rating
Existem algumas escalas para entender se o item (resultado de site, notícia, imagem, mapa e etc.) atende ou não à necessidade do usuário. Na busca pela palavra-chave “lojas colombo” executada no estado do Rio Grande do Sul, o rating trabalha da seguinte maneira:
Combina perfeitamente
Lojas Colombo
Combina bastante
Colombo
Combina
Camisa Colombo
Combina pouco
Cidade de Colombo
Não combina
Raimundo Colombo
Mais exemplos sobre este ponto podem ser encontrados no guideline mencionado anteriormente.
Qualidade da página
Existem três conceitos que descrevem o significado de "Qualidade de Página": Expertise, Autoridade e Credibilidade (chamamos este item de Reputação). São três perguntas simples, mas que valem ser feitas: o autor deste conteúdo é um especialista no tema? O site ou página são uma autoridade sobre o tema? Você confia neste conteúdo?
Páginas de baixa qualidade são o oposto do item anterior: a qualidade do conteúdo é baixa? O conteúdo é insatisfatório? O autor não passa confiança ou não é uma autoridade sobre o assunto? Existem muitos anúncios na página ou algo que possa gerar uma distração?
Ufa, finalmente chegamos ao final do artigo e espero não ter assustado ninguém ou soar mandatário em nada. O conteúdo pode parecer uma teoria sobre Game of Thrones. Entretanto, a ideia foi abrir a discussão sobre o entendimento da ferramenta de busca sobre o significado de uma determinada query (palavra-chave) e também da necessidade do usuário quando este executa a busca.
Comentem, discutam, compartilhem e vamos evoluir juntos nesse material!
Meta-dados: também conhecidos como "dados sobre os dados", são um detalhamento sobre aquela informação em específico.Shards: são os grupos de servidores onde as mais de 30 trilhões de páginas ficam armazenadas, compondo o índice de busca.

 Após essa primeira etapa, entramos na fase de recuperação e score, passando primeiramente pelo envio da palavra-chave para todas as "shards".
Cada uma das "shards" retorna:
Após essa primeira etapa, entramos na fase de recuperação e score, passando primeiramente pelo envio da palavra-chave para todas as "shards".
Cada uma das "shards" retorna:
 Certo, mas afinal, qual a função do "engenheiro de rankings"? As principais são:
Certo, mas afinal, qual a função do "engenheiro de rankings"? As principais são:
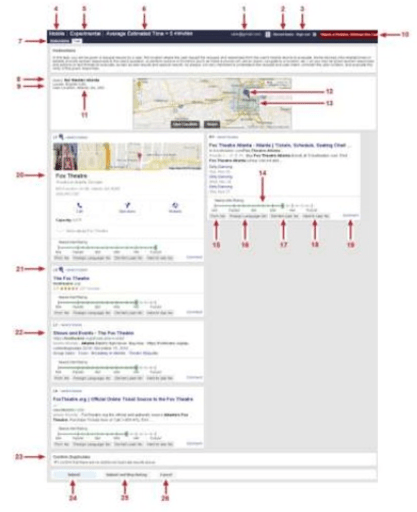 Exemplo de como a ferramenta de coleta (Radar Tools) funciona:
Exemplo de como a ferramenta de coleta (Radar Tools) funciona: